
原文:https://www.aneasystone.com/archives/2017/12/solving-dead-locks-three.html
一、基本的加锁规则
虽然 MySQL 的锁各式各样,但是有些基本的加锁原则是保持不变的,譬如:快照读是不加锁的,更新语句肯定是加排它锁的,RC 隔离级别是没有间隙锁的等等。这些规则整理如下,后面就不再重复介绍了:
常见语句的加锁
- SELECT … 语句正常情况下为快照读,不加锁;
- SELECT … LOCK IN SHARE MODE 语句为当前读,加 S 锁;
- SELECT … FOR UPDATE 语句为当前读,加 X 锁;
- 常见的 DML 语句(如 INSERT、DELETE、UPDATE)为当前读,加 X 锁;
- 常见的 DDL 语句(如 ALTER、CREATE 等)加表级锁,且这些语句为隐式提交,不能回滚;
表锁
- 表锁(分 S 锁和 X 锁)
- 意向锁(分 IS 锁和 IX 锁)
- 自增锁(一般见不到,只有在 innodb_autoinc_lock_mode = 0 或者 Bulk inserts 时才可能有)
行锁
- 记录锁(分 S 锁和 X 锁)
- 间隙锁(分 S 锁和 X 锁)
- Next-key 锁(分 S 锁和 X 锁)
- 插入意向锁
行锁分析
- 行锁都是加在索引上的,最终都会落在聚簇索引上;
- 加行锁的过程是一条一条记录加的;
锁冲突
- S 锁和 S 锁兼容,X 锁和 X 锁冲突,X 锁和 S 锁冲突;
- 表锁和行锁的冲突矩阵参见前面的博客 了解常见的锁类型;
不同隔离级别下的锁
- 上面说 SELECT … 语句正常情况下为快照读,不加锁;但是在 Serializable 隔离级别下为当前读,加 S 锁;
- RC 隔离级别下没有间隙锁和 Next-key 锁(特殊情况下也会有:purge + unique key);
- 不同隔离级别下锁的区别,参见前面的博客 学习事务与隔离级别;
二、简单 SQL 的加锁分析
何登成前辈在他的博客《MySQL 加锁处理分析》中对一些常见的 SQL 加锁进行了细致的分析,这篇博客可以说是网上介绍 MySQL 加锁分析的一个范本,网上几乎所有关于加锁分析的博客都是参考了这篇博客,勘称经典,强烈推荐。我这里也不例外,只是在他的基础上进行了一些整理和总结。
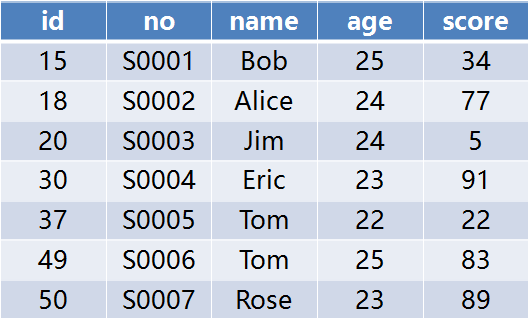
我们使用下面这张 students 表作为实例,其中 id 为主键,no(学号)为二级唯一索引,name(姓名)和 age(年龄)为二级非唯一索引,score(学分)无索引。
这一节我们只分析最简单的一种 SQL,它只包含一个 WHERE 条件,等值查询或范围查询。虽然 SQL 非常简单,但是针对不同类型的列,我们还是会面对各种情况:
- 聚簇索引,查询命中:UPDATE students SET score = 100 WHERE id = 15;
- 聚簇索引,查询未命中:UPDATE students SET score = 100 WHERE id = 16;
- 二级唯一索引,查询命中:UPDATE students SET score = 100 WHERE no = ‘S0003’;
- 二级唯一索引,查询未命中:UPDATE students SET score = 100 WHERE no = ‘S0008’;
- 二级非唯一索引,查询命中:UPDATE students SET score = 100 WHERE name = ‘Tom’;
- 二级非唯一索引,查询未命中:UPDATE students SET score = 100 WHERE name = ‘John’;
- 无索引:UPDATE students SET score = 100 WHERE score = 22;
- 聚簇索引,范围查询:UPDATE students SET score = 100 WHERE id <= 20;
- 二级索引,范围查询:UPDATE students SET score = 100 WHERE age <= 23;
- 修改索引值:UPDATE students SET name = ‘John’ WHERE id = 15;
2.1 聚簇索引,查询命中
语句 UPDATE students SET score = 100 WHERE id = 15 在 RC 和 RR 隔离级别下加锁情况一样,都是对 id 这个聚簇索引加 X 锁,如下:
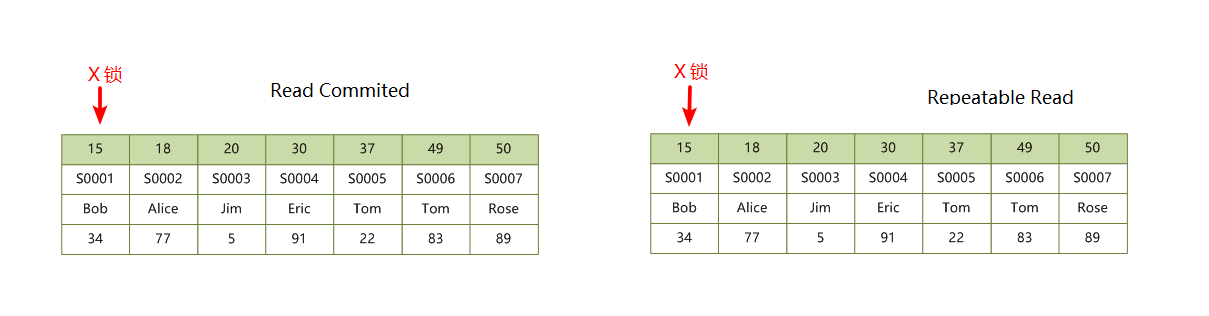
2.2 聚簇索引,查询未命中
如果查询未命中纪录,在 RC 和 RR 隔离级别下加锁是不一样的,因为 RR 有 GAP 锁。语句 UPDATE students SET score = 100 WHERE id = 16 在 RC 和 RR 隔离级别下的加锁情况如下(RC 不加锁):
2.3 二级唯一索引,查询命中
语句 UPDATE students SET score = 100 WHERE no = 'S0003' 命中二级唯一索引,上一篇博客中我们介绍了索引的结构,我们知道二级索引的叶子节点中保存了主键索引的位置,在给二级索引加锁的时候,主键索引也会一并加锁。这个在 RC 和 RR 两种隔离级别下没有区别:
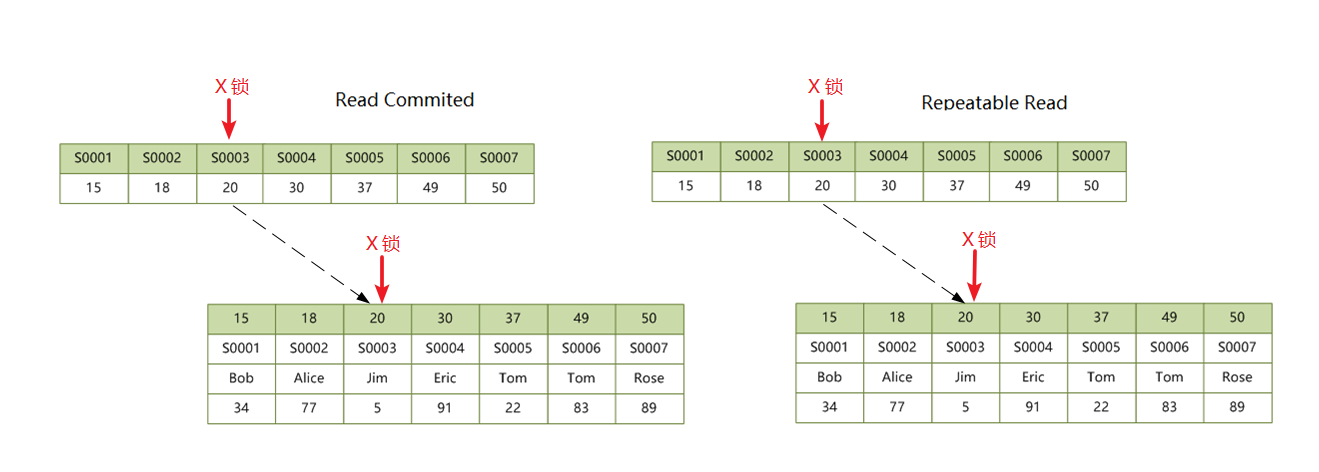
那么,为什么主键索引上的记录也要加锁呢?因为有可能其他事务会根据主键对 students 表进行更新,如:UPDATE students SET score = 100 WHERE id = 20,试想一下,如果主键索引没有加锁,那么显然会存在并发问题。
2.4 二级唯一索引,查询未命中
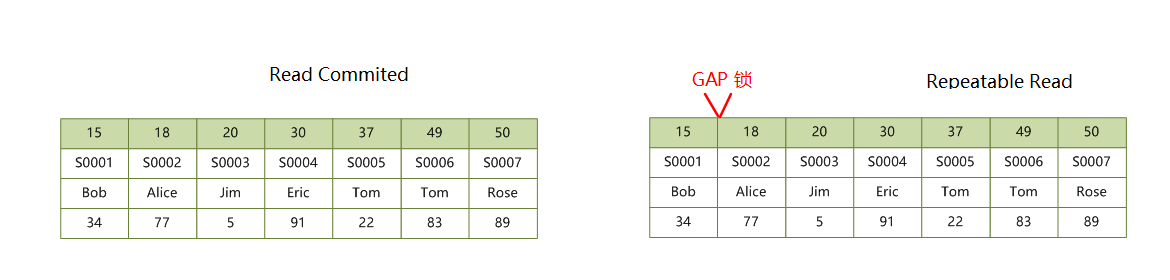
如果查询未命中纪录,和 2.2 情况一样,RR 隔离级别会加 GAP 锁,RC 无锁。语句 UPDATE students SET score = 100 WHERE no = 'S0008' 加锁情况如下:
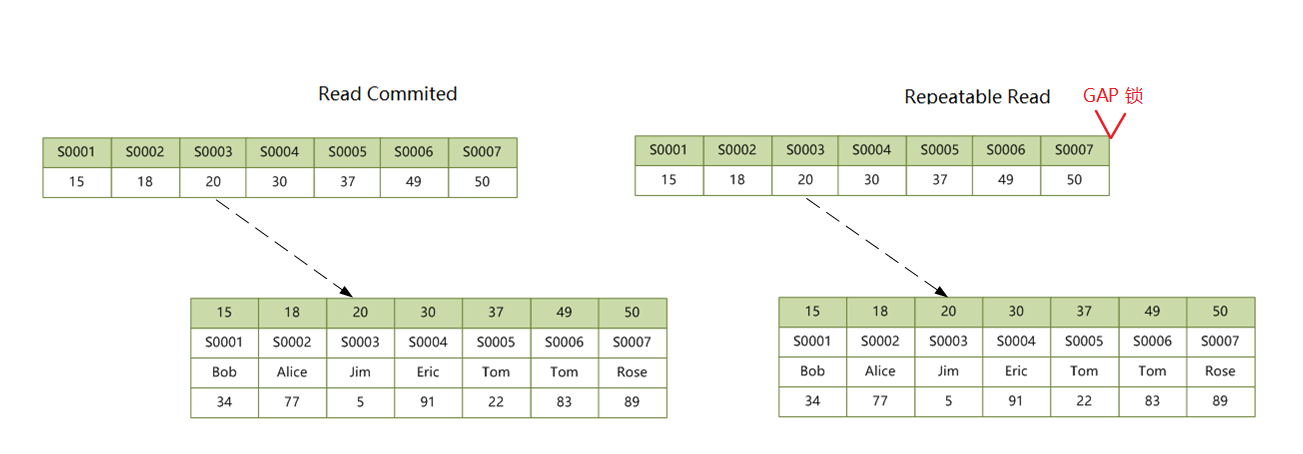
这种情况下只会在二级索引加锁,不会在聚簇索引上加锁。
2.5 二级非唯一索引,查询命中
如果查询命中的是二级非唯一索引,在 RR 隔离级别下,还会加 GAP 锁。语句 UPDATE students SET score = 100 WHERE name = 'Tom' 加锁如下:
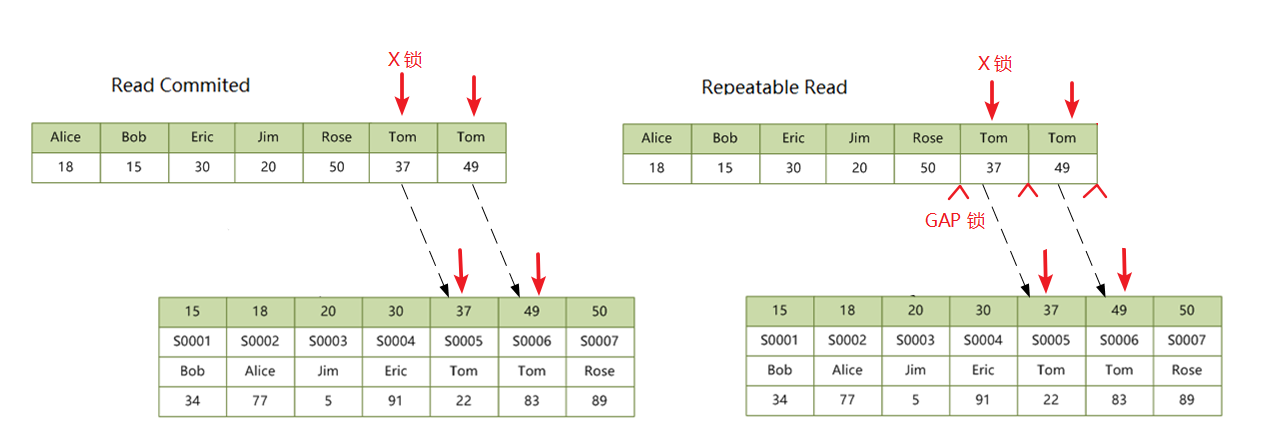
为什么非唯一索引会加 GAP 锁,而唯一索引不用加 GAP 锁呢?原因很简单,GAP 锁的作用是为了解决幻读,防止其他事务插入相同索引值的记录,而唯一索引和主键约束都已经保证了该索引值肯定只有一条记录,所以无需加 GAP 锁。
这里还有一点要注意一下,数一数右图中的锁你可能会觉得一共加了 7 把锁,实际情况不是,要注意的是 (Tom, 37) 上的记录锁和它前面的 GAP 锁合起来是一个 Next-key 锁,这个锁加在 (Tom, 37) 这个索引上,另外 (Tom, 49) 上也有一把 Next-key 锁。那么最右边的 GAP 锁加在哪呢?右边已经没有任何记录了啊。其实,在 InnoDb 存储引擎里,每个数据页中都会有两个虚拟的行记录,用来限定记录的边界,分别是:Infimum Record 和 Supremum Record,Infimum 是比该页中任何记录都要小的值,而 Supremum 比该页中最大的记录值还要大,这两条记录在创建页的时候就有了,并且不会删除。上面右边的 GAP 锁就是加在 Supremum Record 上。所以说,上面右图中共有 2 把 Next-key 锁,1 把 GAP 锁,2 把记录锁,一共 5 把锁。
2.6 二级非唯一索引,查询未命中
如果查询未命中纪录,和 2.2、2.4 情况一样,RR 隔离级别会加 GAP 锁,RC 无锁。语句 UPDATE students SET score = 100 WHERE name = 'John' 加锁情况如下:
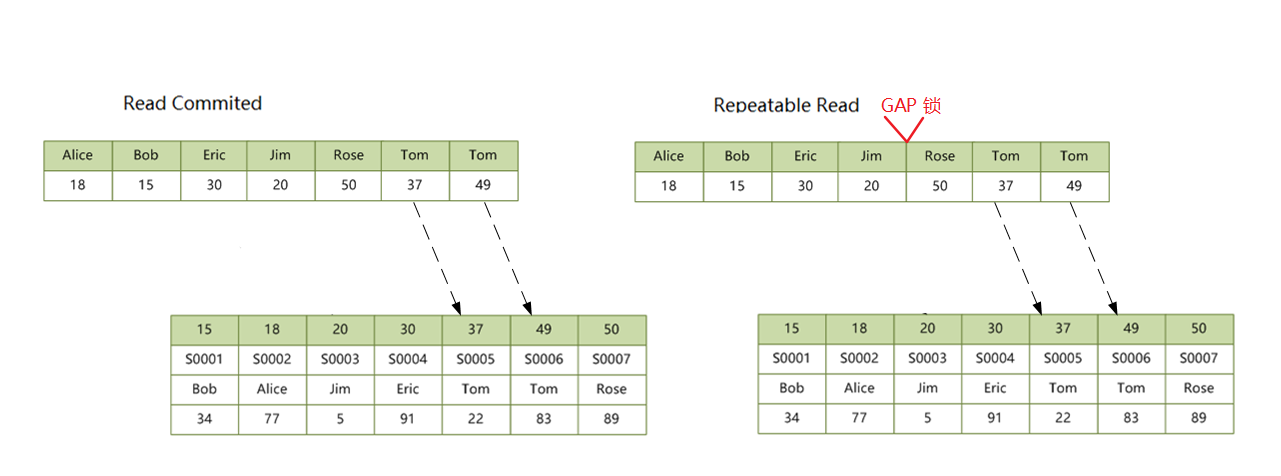
2.7 无索引
如果 WHERE 条件不能走索引,MySQL 会如何加锁呢?有的人说会在表上加 X 锁,也有人说会根据 WHERE 条件将筛选出来的记录在聚簇索引上加上 X 锁,那么究竟如何,我们看下图:
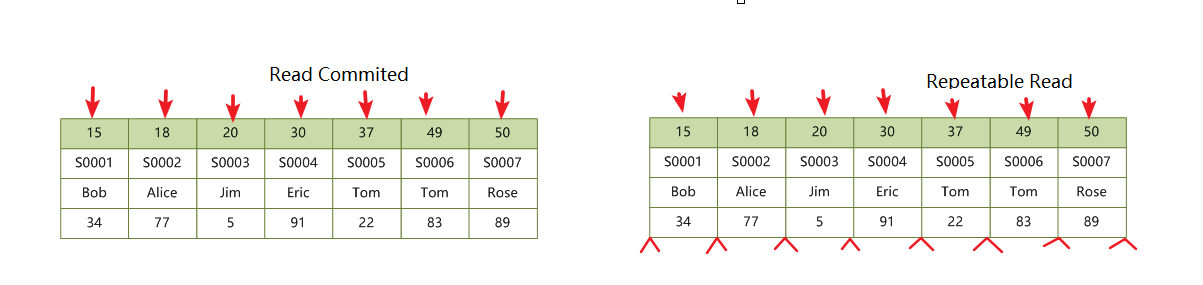
在没有索引的时候,只能走聚簇索引,对表中的记录进行全表扫描。在 RC 隔离级别下会给所有记录加行锁,在 RR 隔离级别下,不仅会给所有记录加行锁,所有聚簇索引和聚簇索引之间还会加上 GAP 锁。
语句 UPDATE students SET score = 100 WHERE score = 22 满足条件的虽然只有 1 条记录,但是聚簇索引上所有的记录,都被加上了 X 锁。那么,为什么不是只在满足条件的记录上加锁呢?这是由于 MySQL 的实现决定的。如果一个条件无法通过索引快速过滤,那么存储引擎层面就会将所有记录加锁后返回,然后由 MySQL Server 层进行过滤,因此也就把所有的记录都锁上了。
不过在实际的实现中,MySQL 有一些改进,如果是 RC 隔离级别,在 MySQL Server 过滤条件发现不满足后,会调用 unlock_row 方法,把不满足条件的记录锁释放掉(违背了 2PL 的约束)。这样做可以保证最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。如果是 RR 隔离级别,一般情况下 MySQL 是不能这样优化的,除非设置了 innodb_locks_unsafe_for_binlog 参数,这时也会提前释放锁,并且不加 GAP 锁,这就是所谓的 semi-consistent read,关于 semi-consistent read 可以参考 这里。
2.8 聚簇索引,范围查询
上面所介绍的各种情况其实都是非常常见的 SQL,它们有一个特点:全部都只有一个 WHERE 条件,并且都是等值查询。那么问题来了,如果不是等值查询而是范围查询,加锁情况会怎么样呢?有人可能会觉得这很简单,根据上面的加锁经验,我们只要给查询范围内的所有记录加上锁即可,如果隔离级别是 RR,所有记录之间再加上间隙锁。事实究竟如何,我们看下面的图:

SQL 语句为 UPDATE students SET score = 100 WHERE id <= 20,按理说我们只需要将 id = 20、18、15 三条记录锁住即可,但是看右边的图,在 RR 隔离级别下,我们还把 id = 30 这条记录以及 (20, 30] 之间的间隙也锁起来了,很显然这是一个 Next-key 锁。如果 WHERE 条件是 id < 20,则会把 id = 20 这条记录锁住。为什么会这样我也不清楚,网上搜了很久,有人说是为了防止幻读,但 id 是唯一主键,(20, 30] 之间是不可能再插入一条 id = 20 的,所以具体的原因还需要再分析下,如果你知道,还请不吝赐教。
所以对于范围查询,如果 WHERE 条件是 id <= N,那么 N 后一条记录也会被加上 Next-key 锁;如果条件是 id < N,那么 N 这条记录会被加上 Next-key 锁。另外,如果 WHERE 条件是 id >= N,只会给 N 加上记录锁,以及给比 N 大的记录加锁,不会给 N 前一条记录加锁;如果条件是 id > N,也不会锁前一条记录,连 N 这条记录都不会锁。
====================== 11月26号补充 =========================
我在做实验的时候发现,在 RR 隔离级别,条件是 id >= 20,有时会对 id < 20 的记录加锁,有时候又不加,感觉找不到任何规律,请以实际情况为准。我对范围查询的加锁原理还不是很明白,后面有时间再仔细研究下,也欢迎有兴趣的同学一起讨论下。
下面是我做的一个简单的实验,表很简单,只有一列主键 id:
1 | show create table t1; |
表里一共三条数据:
1 | select * from t1; |
执行 delete from t1 where id > 2 时加锁情况是:(2, 4], (4, 6], (6, +∞)
执行 select * from t1 where id > 2 for update 时加锁情况是:(-∞, 2], (2, 4], (4, 6], (6, +∞)
可见 select for update 和 delete 的加锁还是有所区别的,至于 select for update 为什么加 (-∞, 2] 这个锁,我还是百思不得其解。后来无意中给表 t1 加了一个字段 a int(11) NOT NULL,竟然发现 select * from t1 where id > 2 for update 就不会给 (-∞, 2] 加锁了,真的非常奇怪。
====================== 12月3号补充 =========================
经过几天的搜索,终于找到了一个像样的解释(但不好去证实):当数据表中数据非常少时,譬如上面那个的例子,select … [lock in share mode | for update] 语句会走全表扫描,这样表中所有记录都会被锁住,这就是 (-∞, 2] 被锁的原因。而 delete 语句并不会走全表扫描。
2.9 二级索引,范围查询
然后我们把范围查询应用到二级非唯一索引上来,SQL 语句为:UPDATE students SET score = 100 WHERE age <= 23,加锁情况如下图所示:
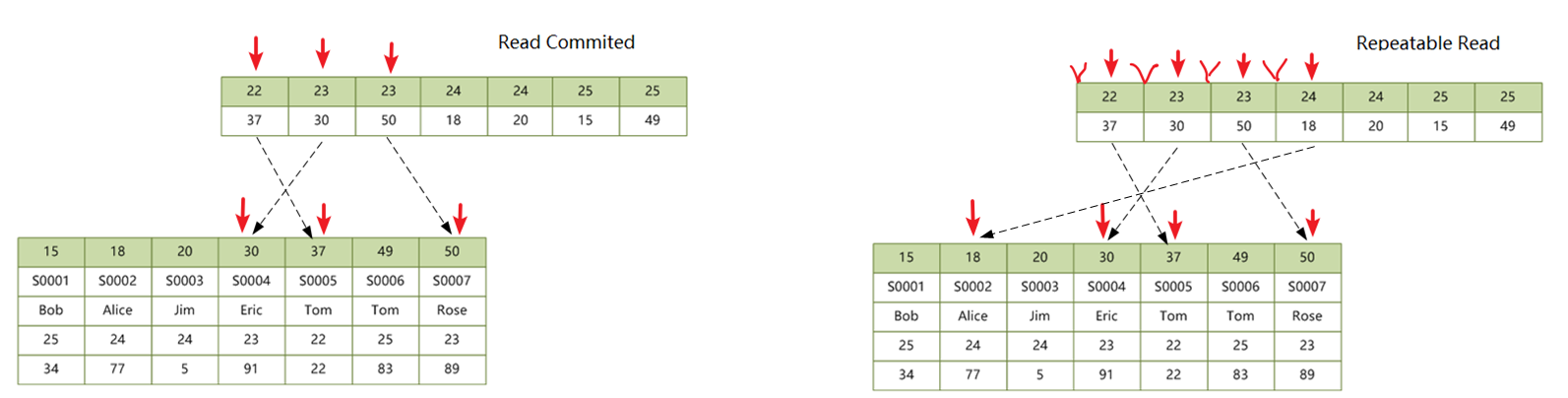
可以看出和聚簇索引的范围查询一样,除了 WHERE 条件范围内的记录加锁之外,后面一条记录也会加上 Next-key 锁,这里有意思的一点是,尽管满足 age = 24 的记录有两条,但只有第一条被加锁,第二条没有加锁,并且第一条和第二条之间也没有加锁。
2.10 修改索引值
这种情况比较容易理解,WHERE 部分的索引加锁原则和上面介绍的一样,多的是 SET 部分的加锁。譬如 UPDATE students SET name = 'John' WHERE id = 15 不仅在 id = 15 记录上加锁之外,还会在 name = ‘Bob’(原值)和 name = ‘John’(新值) 上加锁。示意图如下:
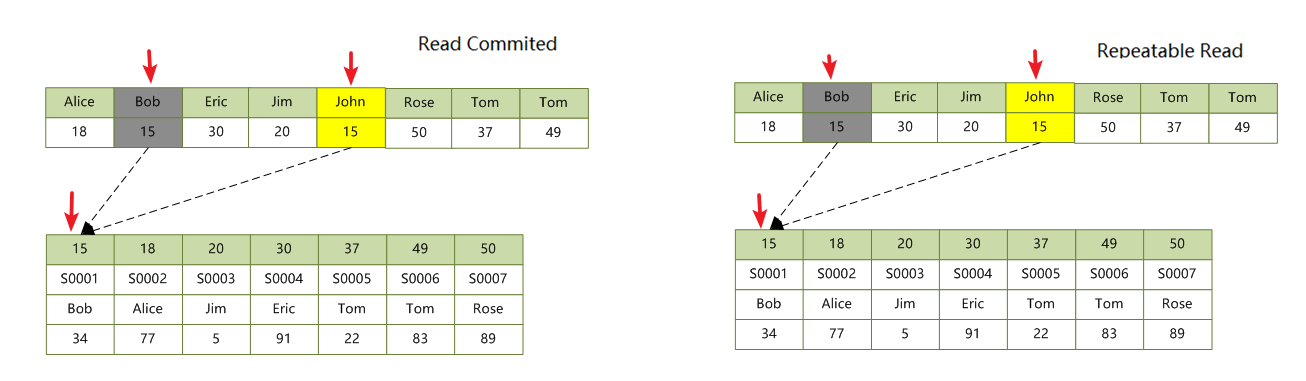
RC 和 RR 没有区别。
三、复杂条件加锁分析
前面的例子都是非常简单的 SQL,只包含一个 WHERE 条件,并且是等值查询,当 SQL 语句中包含多个条件时,对索引的分析就相当重要了。因为我们知道行锁最终都是加在索引上的,如果我们连执行 SQL 语句时会使用哪个索引都不知道,又怎么去分析这个 SQL 所加的锁呢?
MySQL 的索引是一个很复杂的话题,甚至可以写一本书出来了。这里就只是学习一下在对复杂 SQL 加锁分析之前如何先对索引进行分析。譬如下面这样的 SQL:
1 | mysql> DELETE FROM students WHERE name = 'Tom' AND age = 22; |
其中 name 和 age 两个字段都是索引,那么该如何加锁?这其实取决于 MySQL 用哪个索引。可以用 EXPLAIN 命令分析 MySQL 是如何执行这条 SQL 的,通过这个命令可以知道 MySQL 会使用哪些索引以及怎么用索引来执行 SQL 的,只有执行会用到的索引才有可能被加锁,没有使用的索引是不加锁的,这里有一篇 EXPLAIN 的博客可以参考。也可以使用 MySQL 的 optimizer_trace 功能 来对 SQL 进行分析,它支持将执行的 SQL 的查询计划树记录下来,这个稍微有点难度,有兴趣的同学可以研究下。那么 MySQL 是如何选择合适的索引呢?其实 MySQL 会给每一个索引一个指标,叫做索引的选择性,这个值越高表示使用这个索引能最大程度的过滤更多的记录,关于这个,又是另一个话题了。
当然,从两个索引中选择一个索引来用,这种情况的加锁分析和我们上一节讨论的情形并没有本质的区别,只需要将那个没有用索引的 WHERE 条件当成普通的过滤条件就好了。这里我们会把用到的索引称为 Index Key,而另一个条件称为 Table Filter。譬如这里如果用到的索引为 age,那么 age 就是 Index Key,而 name = ‘Tom’ 就是 Table Filter。Index Key 又分为 First Key 和 Last Key,如果 Index Key 是范围查询的话,如下面的例子:
1 | mysql> DELETE FROM students WHERE name = 'Tom' AND age > 22 AND age < 25; |
其中 First Key 为 age > 22,Last Key 为 age < 25。
所以我们在加锁分析时,只需要确定 Index Key 即可,锁是加在 First Key 和 Last Key 之间的记录上的,如果隔离级别为 RR,同样会有间隙锁。要注意的是,当索引为复合索引时,Index Key 可能会有多个,何登成的这篇博客《SQL中的where条件,在数据库中提取与应用浅析》 详细介绍了如何从一个复杂的 WHERE 条件中提取出 Index Key,推荐一读。这里 也有一篇博客介绍了 MySQL 是如何利用索引的。
当索引为复合索引时,不仅可能有多个 Index Key,而且还可能有 Index Filter。所谓 Index Filter,就是复合索引中除 Index Key 之外的其他可用于过滤的条件。如果 MySQL 是 5.6 之前的版本,Index Filter 和 Table Filter 没有区别,统统将 Index First Key 与 Index Last Key 范围内的索引记录,回表读取完整记录,然后返回给 MySQL Server 层进行过滤。而在 MySQL 5.6 之后,Index Filter 与 Table Filter 分离,Index Filter 下降到 InnoDB 的索引层面进行过滤,减少了回表与返回 MySQL Server 层的记录交互开销,提高了SQL的执行效率,这就是传说中的 ICP(Index Condition Pushdown),使用 Index Filter 过滤不满足条件的记录,无需加锁。
这里引用何登成前辈博客中的一个例子(图片来源):
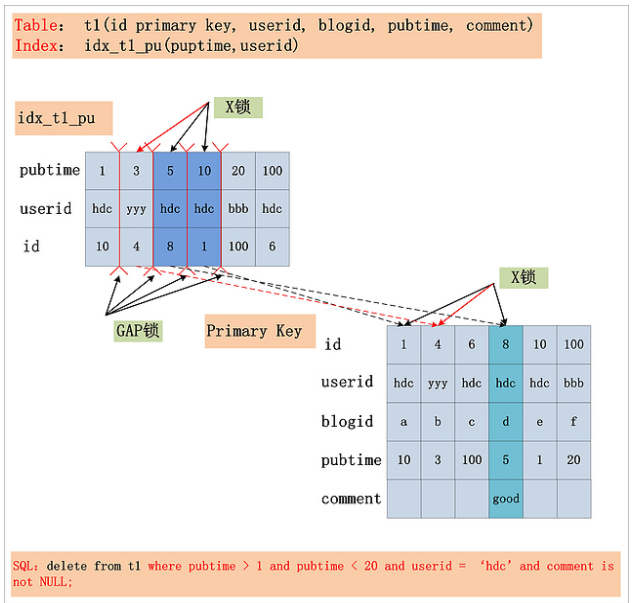
可以看到 pubtime > 1 and pubtime < 20 为 Index First Key 和 Index Last Key,MySQL 会在这个范围内加上记录锁和间隙锁;userid = ‘hdc’ 为 Index Filter,这个过滤条件可以在索引层面就可以过滤掉一条记录,因此如果数据库支持 ICP 的话,(4, yyy, 3) 这条记录就不会加锁;comment is not NULL 为 Table Filter,虽然这个条件也可以过滤一条记录,但是它不能在索引层面过滤,而是在根据索引读取了整条记录之后才过滤的,因此加锁并不能省略。
四、DELETE 语句加锁分析
一般来说,DELETE 的加锁和 SELECT FOR UPDATE 或 UPDATE 并没有太大的差异,DELETE 语句一样会有下面这些情况:
- 聚簇索引,查询命中:DELETE FROM students WHERE id = 15;
- 聚簇索引,查询未命中:DELETE FROM students WHERE id = 16;
- 二级唯一索引,查询命中:DELETE FROM students WHERE no = ‘S0003’;
- 二级唯一索引,查询未命中:DELETE FROM students WHERE no = ‘S0008’;
- 二级非唯一索引,查询命中:DELETE FROM students WHERE name = ‘Tom’;
- 二级非唯一索引,查询未命中:DELETE FROM students WHERE name = ‘John’;
- 无索引:DELETE FROM students WHERE score = 22;
- 聚簇索引,范围查询:DELETE FROM students WHERE id <= 20;
- 二级索引,范围查询:DELETE FROM students WHERE age <= 23;
针对这些情况的加锁分析和上文一致,这里不再赘述。
那么 DELETE 语句和 UPDATE 语句的加锁到底会有什么不同呢?我们知道,在 MySQL 数据库中,执行 DELETE 语句其实并没有直接删除记录,而是在记录上打上一个删除标记,然后通过后台的一个叫做 purge 的线程来清理。从这一点来看,DELETE 和 UPDATE 确实是非常相像。事实上,DELETE 和 UPDATE 的加锁也几乎是一样的,这里要单独加一节来说明 DELETE 语句的加锁分析,其实并不是因为 DELETE 语句的加锁和其他语句有所不同,而是因为 DELETE 语句导致多了一种特殊类型的记录:标记为删除的记录,对于这种类型记录,它的加锁和其他记录的加锁机制不一样。所以这一节的标题叫做 标记为删除的记录的加锁分析 可能更合适。
那么问题又来了:什么情况下会对已标记为删除的记录加锁呢?我总结下来会有两种情况:阻塞后加锁 和 快照读后加锁(自己取得名字),下面分别介绍。
阻塞后加锁 如下图所示,事务 A 删除 id = 18 这条记录,同时事务 B 也删除 id = 18 这条记录,很显然,id 为主键,DELETE 语句需要获取 X 记录锁,事务 B 阻塞。事务 A 提交之后,id = 18 这条记录被标记为删除,此时事务 B 就需要对已删除记录进行加锁。

快照读后加锁 如下图所示,事务 A 删除 id = 18 这条记录,并提交。事务 B 在事务 A 提交之前有一次 id = 18 的快照读,所以在后面删除 id = 18 这条记录的时候就需要对已删除记录加锁了。如果没有事务开头的这个快照读,DELETE 语句就只是简单的删除一条不存在的记录。

注意,上面的事务 B 不限于 DELETE 语句,换成 UPDATE 或 SELECT FOR UPDATE 同样适用。网上对这种删除记录的加锁分析并不多,我通过自己做的实验,得到了下面这些结论,如有不正确的地方,欢迎斧正。(实验环境,MySQL 版本:5.7,隔离级别:RR)
- 删除记录为聚簇索引
- 阻塞后加锁:在删除记录上加 X 记录锁(rec but not gap),并在删除的后一条记录上加间隙锁(gap before rec)
- 快照读后加锁:在删除记录上加 X 记录锁(rec but not gap)
- 删除记录为二级索引(唯一索引和非唯一索引都适用)
- 阻塞后加锁:在删除记录上加 Next-key 锁,并在删除的后一条记录上加间隙锁
- 快照读后加锁:在删除记录上加 Next-key 锁,并在删除的后一条记录上加间隙锁
要注意的是,这里的隔离级别为 RR,如果在 RC 隔离级别下,加锁过程应该会不一样,感兴趣的同学可以自行实验。关于 DELETE 语句的加锁,何登成前辈在他的博客:一个最不可思议的MySQL死锁分析 里面有详细的分析,并介绍了页面锁的相关概念,还原了仅仅只有一条 DELETE 语句也会造成死锁的整个过程,讲的很精彩。
五、INSERT 语句加锁分析
上面所提到的加锁分析,都是针对 SELECT FOR UPDATE、UPDATE、DELETE 等进行的,那么针对 INSERT 加锁过程又是怎样的呢?我们下面继续探索。
还是用 students 表来实验,譬如我们执行下面的 SQL:
1 | insert into students(no, name, age, score) value('S0008', 'John', 26, 87); |
然后我们用 show engine innodb status\G 查询事务的锁情况:
1 | ---TRANSACTION 3774, ACTIVE 2 sec |
我们发现除了一个 IX 的 TABLE LOCK 之外,就没有其他的锁了,难道 INSERT 不加锁?一般来说,加锁都是对表中已有的记录进行加锁,而 INSERT 语句是插入一条新的纪录,这条记录表中本来就没有,那是不是就不需要加锁了?显然不是,至少有两个原因可以说明 INSERT 加了锁:
- 为了防止幻读,如果记录之间加有 GAP 锁,此时不能 INSERT;
- 如果 INSERT 的记录和已有记录造成唯一键冲突,此时不能 INSERT;
要解决这两个问题,都是靠锁来解决的(第一个加插入意向锁,第二个加 S 锁进行当前读),只是在 INSERT 的时候如果没有出现这两种情况,那么锁就是隐式的,只是我们看不到而已。这里我们不得不提一个概念叫 隐式锁(Implicit Lock),它对我们分析 INSERT 语句的加锁过程至关重要。
关于隐式锁,这篇文章《MySQL数据库InnoDB存储引擎中的锁机制》对其做了详细的说明,讲的非常清楚,推荐一读。可以参考上一篇介绍的悲观锁和乐观锁。
锁是一种悲观的顺序化机制,它假设很可能发生冲突,因此在操作数据时,就加锁,如果冲突的可能性很小,多数的锁都是不必要的。Innodb 实现了一个延迟加锁的机制来减少加锁的数量,这被称为隐式锁。
隐式锁中有个重要的元素:事务ID(trx_id)。隐式锁的逻辑过程如下:
A. InnoDB 的每条记录中都有一个隐含的 trx_id 字段,这个字段存在于簇索引的 B+Tree 中;
B. 在操作一条记录前,首先根据记录中的 trx_id 检查该事务是否是活动的事务(未提交或回滚),如果是活动的事务,首先将隐式锁转换为显式锁(就是为该事务添加一个锁);
C. 检查是否有锁冲突,如果有冲突,创建锁,并设置为 waiting 状态;如果没有冲突不加锁,跳到 E;
D. 等待加锁成功,被唤醒,或者超时;
E. 写数据,并将自己的 trx_id 写入 trx_id 字段。
隐式锁的特点是只有在可能发生冲突时才加锁,减少了锁的数量。另外,隐式锁是针对被修改的 B+Tree 记录,因此都是 Record 类型的锁,不可能是 Gap 或 Next-Key 类型。
- INSERT 操作只加隐式锁,不需要显示加锁;
- UPDATE、DELETE 在查询时,直接对查询用的 Index 和主键使用显示锁,其他索引上使用隐式锁。
理论上说,可以对主键使用隐式锁的。提前使用显示锁应该是为了减少死锁的可能性。INSERT,UPDATE,DELETE 对 B+Tree 们的操作都是从主键的 B+Tree 开始,因此对主键加锁可以有效的阻止死锁。
INSERT 加锁流程如下(参考):
- 首先对插入的间隙加插入意向锁(Insert Intension Locks)
- 如果该间隙已被加上了 GAP 锁或 Next-Key 锁,则加锁失败进入等待;
- 如果没有,则加锁成功,表示可以插入;
- 然后判断插入记录是否有唯一键,如果有,则进行唯一性约束检查
- 如果不存在相同键值,则完成插入
- 如果存在相同键值,则判断该键值是否加锁
- 如果没有锁, 判断该记录是否被标记为删除
- 如果标记为删除,说明事务已经提交,还没来得及 purge,这时加 S 锁等待;
- 如果没有标记删除,则报 1062 duplicate key 错误;
- 如果有锁,说明该记录正在处理(新增、删除或更新),且事务还未提交,加 S 锁等待;
- 如果没有锁, 判断该记录是否被标记为删除
- 插入记录并对记录加 X 记录锁;
这里的表述其实并不准确,有兴趣的同学可以去阅读 InnoDb 的源码分析 INSERT 语句具体的加锁过程,我在 《读 MySQL 源码再看 INSERT 加锁流程》 这篇博客中有详细的介绍。